【数据分析】从零开始带你了解商业数据分析模型——深度学习之多层感知器(下)

本文摘要(由AI生成):
本文主要探讨了如何选择合适的超参数来加速多层感知器模型的学习过程,并介绍了如何在 Altair Knowledge Studio 中使用多层感知器。在多层感知器模型的学习过程中,超参数的选择非常重要,常见的超参数包括模型迭代循环次数、学习速率、深度学习隐藏层的层数等。为了优化超参数,可以选择合适的损失函数、激活函数、合理运用 Batch Normalization 和 Dropout 技巧等。Altair Knowledge Studio 中的多层感知器是基于 Keras 框架建立的,它提供了一个可以拖拉拽的易用界面,用户无需编写复杂的 Python 代码,在模型节点的第一个界面,用户需要确立训练数据集和验证数据集,并设定好因变量、自变量和无需考虑的变量。在超参数设置界面,用户可以自定义多层感知器的模型架构。
从上一个章节的介绍中,我们主要了解深度学习(特指多层感知器)的一些基本情况,以及它背后复杂的计算过程。
参数学习的每一次迭代,都会消耗巨大的运算资源和时间。因此本篇我们来谈谈如何选择合适的超参数来加速模型的学习过程。
1
多层感知器的建模优化
1
多层感知器的建模优化
在机器学习的上下文中,模型超参数指的是在建模学习过程之前即预设好的参数。他们不是通过训练得到的参数数据。
常见的超参数有:模型迭代循环次数、学习速率、深度学习隐藏层的层数等等。
超参数的优化方式和途径有很多,这个章节主要会从两个方面来探讨优化方法,即:
学习训练速度
模型稳定性
01
学习训练速度
选择合适的损失函数
在模型训练结束后的损失函数报告中,我们有时会观察到下图所示的现象:在最开始和最后的迭代过程中,模型的学习速率很慢,然而在迭代的中间过程中,模型的学习速率相对较快。

接下来,我们会用一个样本案例来帮助大家解析上面这个现象出现的原因。
假设,我们现在有一个单层单节点的神经网络模型。将输入数据记作x,真实输出数据记作y。模型的线性运算我们可由下式来表示:

假设我们的非线性运算(也叫做激活函数)使用sigmoid函数,并记作:


这个案例中,我们将常见的L2范数函数作为损失函数,即:

基于权重w求出损失函数L的偏微分,我们可以得出:

逐步分析上述偏微分的成分:
(δ(wx+b)-y):表示预测值和真实值之间的差值。如果它两的偏差太大,参数更新时速率也会很大;
x:代表的是输入数据。如果输入数据很大,模型学习时参数更新速率也理应很快;
δ'(wx+b):代表的是激活函数的导数。
通过观察sigmoid函数的图像,大家也许就会发现,当函数输入值过小或者过大时,函数的增长率是极度缓慢的!这其实也就解释了为什么有的时候模型的学习速率会在两端迭代时相对缓慢。

为加快模型学习速度,我们通常会更聪明的选择损失函数,比如交叉熵损失函数 ,即:

假设我们依然使用sigmoid函数作为激活函数,通过相应的微分运算之后,我们可以得出交叉熵损失函数的偏微分为:

从上面的公式,我们可以观察到,我们已经避开了sigmoid函数的导数部分。所以,大多数时候我们能够得到一个更合理更平滑的模型学习过程。
除了交叉熵函数,其他常见的损失函数还有softmax损失函数。感兴趣的读者可以自行翻阅资料或与作者进行进一步沟通。
选择合适的激活函数
回忆一下上一章节提到的案例,我们可以发现,激活函数不仅存在于输出层,它还同时存在于每一个隐藏层。所以它的选择除了会影响求损失函数的偏微分结果,还会影响每一个隐藏层的求偏微分结果。
因此为每一层隐藏层选择合适的激活函数,也会大大加快模型的学习速率。

回顾一下激活函数的一些基本要求:
首先它需要是非线性的函数。如果它是一个线性函数的话,我们就可以把激活函数和前面的线性运算组合起来成为一个全新的线性运算。但这样也就没有了隐藏层的意义;
其次它必须是可以求导的函数。因为参数的更新规则是基于每一层运算表达式的偏微分求得的;
最后,激活函数的导数最好是可以维持在一个相对稳定的数值。
基于上述的三点考量,ReLU函数成为了一种常见的激活函数选项。
如下图最左边所示,最基本的激活函数可以有表达式表示。即,当输入大于零时,ReLU函数的导数为非零常数,当输入小于零时,ReLU函数的导数为零。当然ReLU函数也存在两种不同的变型。他们主要是为了处理当输入值小于零时,模型的学习速率。
由此可见,将ReLU函数作为激活函数可以有效地避开我们上述提到的问题,从而大大的加快参数学习过程。
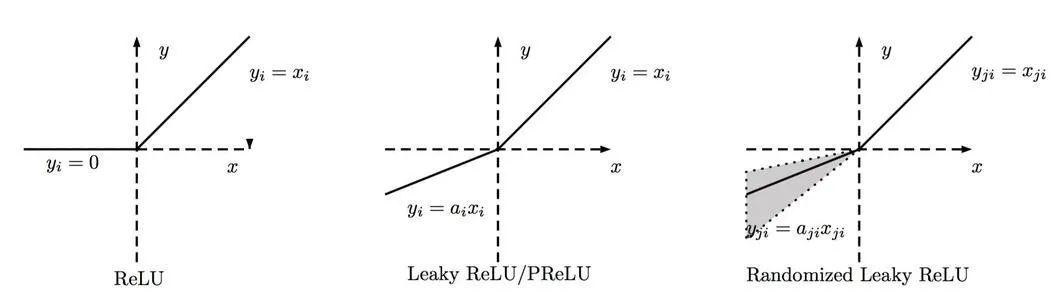
尽管ReLU函数在模型训练速度上表现优异, sigmoid函数和另一种tanh函数依然有作为激活函数存在的意义。因为它们都是良好二分类器。
仔细观察下图的右边两个函数的分布情况,我们可以看到它们都将近乎一半的,输入值较小的数推向了0/-1,并将另一半的,输入值较大的数拉向了1。
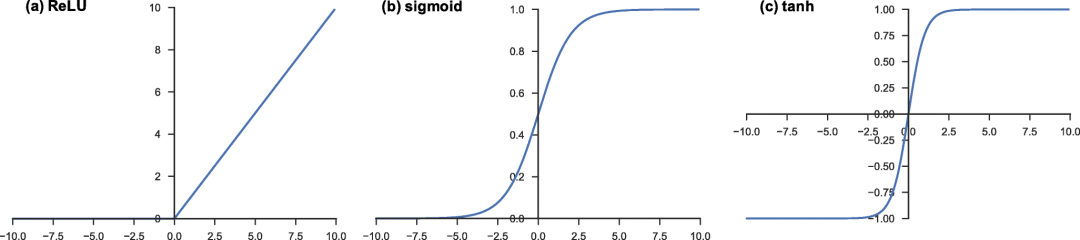
所以如果我们对数据,对深度学习的模型框架设计中有很强的自信的话,我们可以大胆的在隐藏层中采用sigmoid函数或tanh函数作为激活函数,使得模型的最终的分类效果表现得更为优异。
02
模型稳定性
通常来说,深度学习的每一次参数学习并不会使用全部的数据集。训练开始时,我们通常都会抽样出一批数据,并将它们称作batch,样本的个数叫做batch size。
对于每一个统计模型来讲,输入值的分布情况一定会显著的影响到最终的模型学习结果。即,不同的训练样本输入会导致不同的参数训练结果。
这一个特性在深度学习的上下文中尤其的关键。因为在深度学习的模型框架中,每一层的输出值都会作为下一层的输入值使用。所以输入层的样本数据分布情况,会被隐藏层无限放大到输出层。
为了应对这种训练结果不稳定的情况,我们通常会采用一种常见的归一方法,即Batch Normalization。
如下图步骤所示,BN会对样本数据作出一定的标准化处理,从而改变样本的分布,使其输入分布更加的稳定。每一层达到稳定输入分布后,它会使得损失函数的优化空间变得更加平滑,即参数更新时的梯度能够更加顺滑,从而避免了梯度爆炸或弥散等现象。

通常与Batch Normalization一起使用的技巧叫做Dropout。Dropout 指的是在模型学习过程中,模型会随机的去忽略一些神经节点。
忽略掉那些神经节点后的学习结果会更加具有普适性,并更少的依赖某一些特定的神经节点。Dropout也是深度学习中防止学习过拟合的一种关键技巧。
03 小结
简单归纳一下上述提到的优化超参数的方法:
选择合适的损失函数
选择合适的激活函数
合理运用Batch Normalization和Dropout
当然了,除此之外,优化超参数的技巧还有很多。比如引入深监督、适当调节学习率和引入梯度阶段等。如果读者有兴趣的话,可以在评论区留言,如果感兴趣的人多的话,我们可以后期出一篇专题做进一步介绍。
2
在Altair KnowledgeStudio中
实操多层感知器
2
在Altair KnowledgeStudio中
实操多层感知器
Altair Knowledge Studio中的多层感知器是基于Keras框架建立的。它抛开了复杂的基于Python的编码语言,并直接将其建模功能封装好,为用户提供了一个可以拖拉拽的易用界面。
下面我们省略掉前期的数据导入及节点连接的步骤,直接进入模型超参数的设置界面。
模型节点的第一个界面主要是为了确立清楚训练数据集和验证数据集。与此同时,我们还需设定好数据集中我们所关心的因变量(可以是多个),自变量和模型无需考虑的变量。

点击下一步,我们可以来到更详细的超参数设置界面。如下如所示:
界面的最上面部分是自定义多层感知器的模型架构,比如有多少隐藏层,每个隐藏层的神经节点数,以及相应的激活函数;
界面的中部提供了引入Batch Normalization 和Dropout的勾选项;
界面的最下面部分则是帮助用户设置迭代次数,样本大小及参数更新规则等功能。
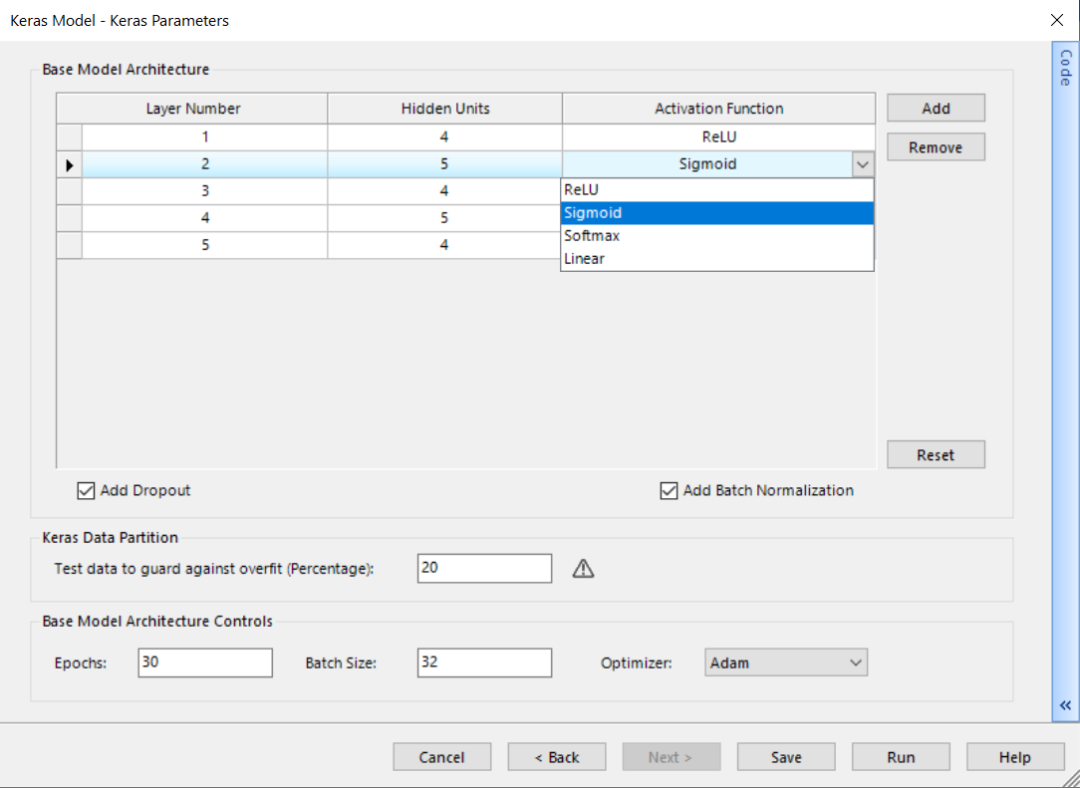
值得一提的是,在每个界面的最右边,大家会看见一个“Code”的边栏。点开它的话,大家就可以看见如何在Keras框架下,用Python语言实现我们上述所提及的模型设置。
因为空间有限,下图仅仅是Python语言实现的一小部分截图: