Broadcom 使用 Spectre FMC(Fast-MC)快速蒙特卡罗 进行时序变化分析

本文翻译转载于:Cadence Blog
作者:Vinod Khera
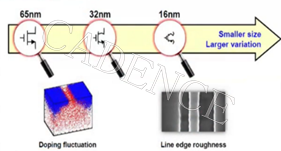
对于最新的微型半导体制作工艺而言,制程工艺变化和器件不匹配带来了深远影响。复杂制程工艺也会影响器件生产的可变性,进而影响整体良品率。 蒙特卡洛(MC)仿真使用重复的随机抽样方法,将工艺变化与电路性能和功能联系起来,从而确定它们对良品率的影响。然而,要进行全面的设计空间研究,设计团队需要完成大量的 MC 仿真才能达到必要的可信度。
一个芯片上的数十亿个元件,再加上工艺变化和器件不匹配,我们能运行数十亿次统计仿真并耗费大量时间进行验证吗?
运行数百万次甚至数十亿次仿真所需的时间和运算资源是不切实际的,因此,我们迫切需要在提高效能的同时满足统计准确度要求。使用 Cadence Spectre FMC Analysis,Broadcom 取得了良好的成果,并且显著提升了生产力。此外,Spectre 仿真的多处理器模式在保证准确度的同时进一步缩短了运行时间。本文将探讨 Broadcom 借助 Spectre FMC 实现的准确度和性能提升,内容摘录自 Broadcom 团队之前的 CadenceLIVE Silicon Valley 2024 演讲。
为何制程工艺变化总是捉摸不定?
为何制程工艺变化总是捉摸不定?
半导体代工厂通过开发统计模型来准确形容器件级别的变化。这样便可通过兼顾工艺变化的设计技术来最大程度降低集成电路(IC)故障的可能性。MC 仿真可使用这些统计模型来识别最坏情况并确保良品率符合预期。然而,这些仿真需要耗费大量的计算资源和时间,对于芯片上经常使用且具有低故障要求的设计模块来说更是如此,例如标准单元、存储位单元和模拟 IP(ADC、DAC、PLL 和带隙基准等)。
尽管仿真工具和大规模计算资源(如多核和云计算)方面已经非常先进了,执行计算密集型 MC 仿真仍然不切实际,多数情况下根本不可能完成。对于高 sigma MC 分析来说更是如此,这里可能需要超过 10 亿次仿真才能获得高良品率。例如,用 25 亿个样本来确认6σ。
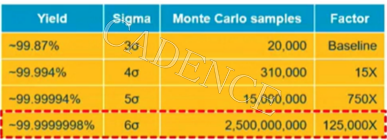
为了在更少的仿真次数和更短的时间内准确估计良品率并判断最坏情况,半导体行业需要使用 EDA 工具。要实现快速、精确的高 sigmaMC 分析,具有一流仿真能力的先进 EDA 解决方案必不可少。
解决方案:
Cadence Spectre FMC Analysis
为了克服上述挑战,Cadence 开发了 Spectre FMC Analysis,将其作为 Spectre Simulation Platform 的一部分,引领行业步入高性能 SPICE 精确电路仿真。
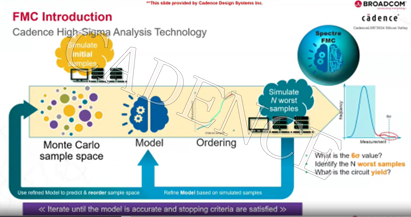
它使用人工智能增强技术,以便:
● 在不影响统计准确度的情况下,尽早、尽快地估计良品率
● 发现统计异常值和最坏情况样本
● 与传统 MC 分析相比,在大幅度减少的仿真次数内提取有用的统计信息
Broadcom 为何选择采用
Spectre FMC Analysis?
Broadcom 为何选择采用
Spectre FMC Analysis?
Broadcom 需要的解决方案必须满足以下要求:能够准确地测量和验证变化模型、具有成本效益并且能无缝整合进现有的 IC 设计流程。此外,还必须具备可扩展性,以满足当下和未来的设计需求。通过与 Cadence 合作,Broadcom 将 Spectre FMC Analysis 用于与时序相关的准确度和分析项目中。
该产品为 Broadcom 带来的好处包括:
● 在高 sigma 下获得高精度
● 应用现有 License Pool 的能力
● 命令行界面 (CLI) 友好
● 轻松整合进现有的 IC 设计流程 Distributed processing
● 分布式处理
● 易于扩展
● 变化准确度认证
案例研究:
Non-Gaussian 分布
为了研究 Spectre FMC 的准确度和性能,Broadcom 团队提出了一个具有 long tail 的案例,该案例不是严格的 Gaussian 分布。
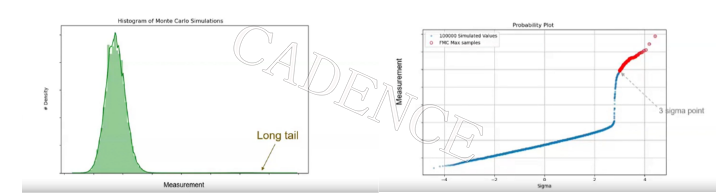
结果表明,Spectre FMC 有能力处理这样充满挑战的分布。通过对比传统 MC 和 Spectre FMC 的性能数据,Broadcom 团队获得了更大的信心。

如果不使用 Spectre FMC Analysis,处理每个作业需要 12 小时,总运行时间约为 245 个月的 CPU 时间,需要使用 1000 个 Spectre License。使用 Spectre FMC,每个作业平均需要 0.2 小时左右,需要使用 300 个 Spectre License,总 CPU 时间也缩短为 14 个月。在 Spectre FMC Analysis 的助力下,Broadcom 在一个月左右的时间内完成了该项目,证明该产品能够带来显著的性能提升。
Cadence Spectre FMC 优势
Cadence Spectre FMC 优势
在与 Broadcom 现有 IC 设计流程无缝整合的同时,Spectre FMC 还大大提高了准确度和性能。在适当的许可条件下运行时,Broadcom 每个 CPU 处理每个作业的效率提升 60 倍左右。即便减少 License 的数量,该产品带来的优势仍然十分显著,整体性能大约提高了 18 倍。Broadcom 提到,使用 Spectre FMC 的主要优势在于提升精确度和显著缩短运行时间。确保有足够的 License Pool 至关重要。此外,该产品的命令行简单易用,且具有强大的可扩展性,非常适合用于高效探索整个设计空间。



