数据驱动框架下的材料科学与工程(material science and engineering)
文一:

由自然语言处理和信息抽取驱动的数据驱动的材料研究
摘要:
随着数据科学和机器学习在社会各个方面的出现,尤其是在科学领域,人们越来越重视获取数据。基于所探索的材料类别的显著范围和感兴趣的材料特性的多样性,材料科学中的数据尤其具有异质性。这导致了范围在许多数量级的数据,这些数据可能表现为数字文本或基于图像的信息,这需要定量解释。因此,通过改编自自然语言处理领域的技术,跨领域自动消费和编纂科学文献的能力具有巨大的潜力,可以解锁和生成数据科学和机器学习所需的丰富数据集。这篇综述侧重于材料科学文献的自然语言处理和文本挖掘的进展和实践,并强调了在文章的图表中提取文本之外的额外信息的机会。我们讨论并举例说明了对材料进行自然语言处理的几个原因,包括数据汇编、假设发展以及理解领域内和跨领域的趋势。详细介绍了当前和新兴的自然语言处理方法及其在材料科学中的应用。然后,我们讨论材料科学领域的自然语言处理和数据挑战,未来的方向可能会被证明是有价值的。

图:高能物理、天文学和天体物理学中大型集中式数据集与材料物理学中异构、分散数据的比较。与其他领域不同,材料科学缺乏足够的动力来实现数据集中,这不仅是因为数据如此多样化,还因为数据来自各种独立科学家和实验室来源。由于科学家研究的材料种类繁多,材料科学领域的数据尤其异质。数据显示为数字文本或基于图像的信息,这需要定量解释。

图:自然语言处理示意图,包括每个步骤的工具和模型示例。很明显,大多数自然语言提取遵循类似的方法: (1)获取相关文本资源,(2)将文本处理成单独的术语(也称为标记化) ,(3)文档分割和段落分类,(4)将标记识别为信息类,(5)实体关系提取,(6)命名实体链接

图:图像提取示意图,包括来自显微镜图像或分子结构的例子。科学文献中的数据来源于基于图像的计量学,主要来源于(扫描)透射电子显微镜和原子力显微镜。尽管这些图像包含了关于材料结构的大量定量数据,但是大多数图像在其周围的文本中都进行了定性的讨论。这些数据可以揭示特别重要的依赖于纳米技术或晶体学的研究问题。该图提供了从文本中提取此信息的路径。
文二:

一种用于数据驱动材料发现的设备流水线设计
摘要:
世界需要新材料来刺 激我们经济的关键部门的化学工业:环境和可持续性、信息存储、光通信和催化。然而,几乎所有的功能材料仍然是通过“试错”发现的,其中缺乏可预测性是技术创新的主要材料瓶颈。目前,材料发现的平均“分子到市场”交付时间为20年。正如材料基因组计划所强调的那样,这对工业需求来说太长了,该计划的宏伟目标是将平均分子到市场的交付周期缩短4倍。只有采用一种全新的材料发现方法,才能现实地实现进展中如此巨大的变化。幸运的是,一种全新的材料发现方法 正在出现,通过这种方法,人工智能的数据科学提供了一种有前景的解决方案,可以加快这些平均分子到市场的交付周期。这种方法被称为数据驱动的材料发现。鉴于“大数据”、人工智能和高性能计算(HPC)的及时和重大进展,其广阔的前景直到最近才成为现实。政府监管的数据和文献开放访问要求刺 激了对海量数据集的访问。可以挖掘数据并在其中找到模式的自然语言处理(NLP)和机器学习(ML)工具正在成为主流。Exascale HPC功能可以帮助数据挖掘和模式识别,也可以通过计算生成自己的数据,现在我们已经掌握了。这些及时的进展为开发数据驱动的材料发现策略提供了一个理想的机会,以系统地设计和预测特定设备应用的新化学品。该账户展示了数据科学如何通过四步“设计到设备”的管道来提供材料发现,该管道包括(1)数据提取、(2)数据富集、(3)材料预测和(4)实验验证。同源化学和性质信息的大规模数据库首先由ChemDataExtractor等“化学感知”自然语言处理工具伪造,并使用机器学习方法和高通量量子化学计算进行丰富。然后,可以通过挖掘这些数据库来预测定制应用的新材料,这些数据库具有已知可提供功能材料的化学结构和物理性质之间关系的算法编码。这些可以采取分类、枚举或机器学习算法的形式。数据挖掘工作流程将这些预测简短地列出给少数几个主要的候选材料,然后进行实验验证。正在开发这种从设计到设备的方法,为加速发现功能应用的新化学品提供路线图。所提供的案例研究证明了其在光伏、光学和催化应用方面的实用性。虽然该账户侧重于物理科学的应用,但所讨论的通用管道很容易转移到生物学和医学等其他科学学科。
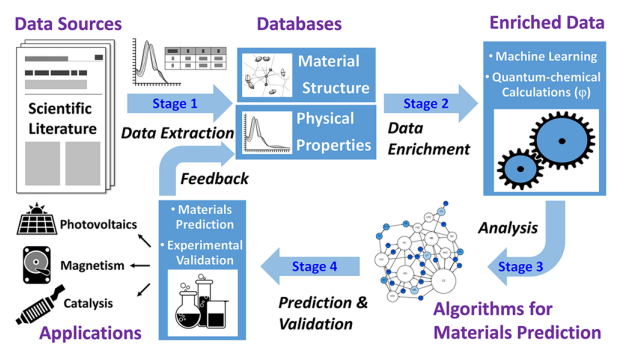
图:数据驱动材料发现的四步设计到设备方法的总体工作流程

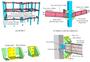
图:(a) 化学和性质空间及其结构-功能关系的概念说明,为挖掘这些数据源提供了知识库。(b) 通用数据挖掘工作流程,将化学数据过滤到连续的短列表中,在那里它们遵循适合给定材料应用的结构-功能关系,直到只剩下少量材料;它们服从所有关系,因此代表领先的候选材料预测。

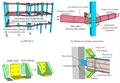
图:化学感知的自然语言处理文本挖掘工具 ChemData萃取器的操作工作流程

图:使用人工神经网络预测优化催化过程的机器学习算法示例。
文三:

基于数据驱动的原子模拟材料模型
摘要:
经典分子动力学模拟材料的中心近似是用来计算原子受力的原子间势。用传统的方法构造可行的函数形式和找到准确的参数化势,需要付出巨大的努力和创造性。机器学习已经成为开发准确而强大的原子间势能的一种有效的替代方法。从一个非常普遍的模型形式开始,势能直接从电子结构计算的数据库中学习,因此可以被视为量子模拟和经典原子模拟之间的多尺度联系。不准确的外推风险存在于狭窄的时间和长度范围之外,这两种方法可以直接进行比较。在这项工作中,我们使用频谱邻域分析势(SNAP) ,并显示了如何可以产生最小的插值误差拟合,这也是鲁棒的外推超越训练。为了证明这种方法,我们已经开发了一个适用于所有二元化合物的钨铍电位。随后,在固体钨的(001)表面进行了大规模的分子动力学模拟。机器学习 W-Be 电位产生一个与缺陷形成能量的量子计算一致的注入结构的种群。预测了很浅(< 2nm)的 Be 平均注入深度,这可能解释了铍存在下 ITER 偏滤器的降解。

图:由31k 个原子组成的 NVE MD 模拟的模拟速率(ns/day)与 SNAP 电位中使用的描述符数目之间的关系。

图:拟合SNAP电位的工作流程。

图:(左)钨材料性能预测包括在 SNAP 优化回路表示为百分比误差的 DFT 预测。由于空位结合能(0.12 eV)的绝对值很小,EAM 的误差百分比比这里显示的 SNAP 电位大得多。(右)铍材料性能预测,也包括在优化程序。这里显示的两个 SNAP 电位都显著改进了现有的自组织形成能的 BOP 预测。
文四:

加速材料设计的数据驱动策略
摘要:
近年来,随着机器学习和人工智能的出现,正在进行的自然科学革命引发了材料科学界的极大兴趣。可实现材料空间的固有高维性使得传统方法对于大规模探索无效。针对日益复杂的问题开发的现代数据科学和机器学习工具是一种有吸引力的替代方案。一场迫在眉睫的气候灾难要求在可能采取行动的几年内彻底改革现有技术,实现清洁能源转型。应对这场危机需要以前所未有的速度和规模开发新材料。例如,有机光伏有潜力在很大程度上取代现有的硅基材料,并开辟新的应用领域。近年来,有机发光二极管已成为数字屏幕和便携式设备的最先进技术,并通过柔性显示器实现了新的应用。网状框架允许原子精确合成纳米材料,并有望通过实现从气体储存、气体分离、电化学储能到纳米医学的多功能纳米颗粒的潜力,彻底改变该领域。在最近的十年里,模拟和机器学习在性质预测、性质优化和化学空间探索中的全面应用,以及计算能力和算法效率的显著进步,促进了所有这些领域的重大进展。在本报告中,我们回顾了我们团队在材料科学机器学习这一蓬勃发展的领域的最新贡献。我们首先总结了我们小组所涉及的最重要的材料类别,重点关注有机电子材料和晶体材料等小分子。具体而言,我们强调了我们用于加快发现和推导材料设计策略的数据驱动方法。随后,我们的重点放在我们团队开发和使用的数据驱动方法上,详细阐述了高通量虚拟筛选、反向分子设计、贝叶斯优化和监督学习。我们讨论了它们的总体思想、工作原理及其用例,并举例说明了在数据驱动的材料发现和设计工作中的成功实施。此外,我们详细阐述了这些方法的潜在陷阱和剩余挑战。最后,我们对该领域进行了简要展望,因为我们预计在材料发现和设计活动中会越来越多地采用和实施大规模数据驱动的方法。

图:热激活延迟荧光有机发射器的逆向设计工作流程,从选择碎片到设备集成和测试。

图:使用超分子变分自动编码器(SmVAE)的自动网状框架(RF)发现平台。

图:高通量虚拟筛选从大的候选空间开始(例如,如图所示,组合生成)。使用虚拟筛选,大多数候选人被淘汰,这样可以进行更少(更昂贵和耗时)的实验测试。

图:分子特性监督式学习的工作流程。已知(标记)数据集用于优化模型,该模型随后用于估计未知(未标记)数据集的分子特性。
文五:

用于数据驱动材料设计的各种集成模拟(JARVIS)联合自动化存储库
摘要:
各种集成模拟联合自动化库(JARVIS)是一个集成基础设施,用于使用密度泛函理论(DFT)、经典力场(FF)和机器学习(ML)技术加速材料发现和设计。JARVIS的动机是材料基因组计划(MGI)原则,即开发开放存取数据库和工具,以减少材料发现、优化和部署的成本和开发时间。JARVIS的主要功能有:JARVIS-DFT、JARVIS FF、JARVIS-ML和JARVIS工具。到目前为止,JARVIS由大约40000种材料和大约100万个JARVIS-DFT计算特性、大约500种材料和≈110个力场以及大约25 ML JARVIS-ML材料特性预测模型组成,所有这些模型都在不断扩展。JARVIS工具提供用于运行和分析各种模拟的脚本和工作流。我们将计算数据与实验或高保真度计算方法进行比较,以评估预测中的误差/不确定性。除了现有的工作流程外,作为数据驱动材料设计范式的一部分,该基础设施还可以支持各种其他技术上重要的应用程序。JARVIS数据集和工具可在以下网站上公开获取:https://jarvis.nist.gov.

图:基于长度和时间尺度的计算材料设计技术。我们主要集中在计算方法的最低两个层次,DFT 和 MD,但我们结合其他模拟方法的具体应用。

图:JARVIS 基础设施概述。对于给定的材料性能指标,几个 JARVIS 组件可以一起工作,以设计优化的或全新的材料。

图:JARVIS工具包的三个主要组件及其功能。

图:JARVIS中的三个主要数据库及其内容摘要。