论文学习|第三篇-综述-无监督深度迁移学习在智能故障诊断中的应用:(标签不一致的UDTL)

非常尊重并感谢科研人员做出的辛勤贡献!若有侵权,烦请联系处理!
若有翻译不当之处,恳请批评指正!
本篇综述详细阐述了智能故障诊断中比较热门的无监督学习迁移学习方法(UDTL),包括定义及分类、已有学者工作、开源基准代码等。适合迁移学习方向初学者系统学习入门。
本篇将介绍第2篇:标签不一致的UDTL、多域UDTL
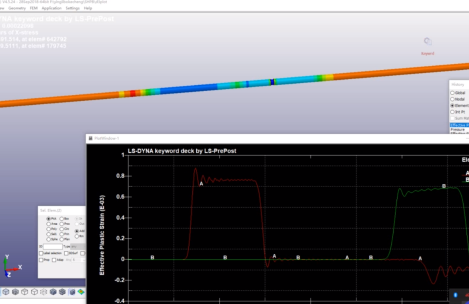
正文共:7147字 6图
预计阅读时间:16分钟
论文信息
论文题目:Applications of Unsupervised Deep Transfer Learning to Intelligent Fault Diagnosis: A Survey and Comparative Study
期刊、年份:Transaction on instrument and measurement,2021
作者:Zhibin Zhao, Qiyang Zhang, Xiaolei Yu, Chuang Sun, Shibin Wang, Ruqiang Yan, Xuefeng Chen
机构:The State Key Laboratory for Manufacturing Systems Engineering, Xi’an Jiaotong University, Xi’an 710049, China
目录
1. 引言
2. 背景和定义
2.1 UDTL的定义
2.2 基于UDTL的IFD分类
2.3 基于UDTL的IFD动机
2.4 主干网络的结构
3. 标签一致的UDTL(Label-consistent UDTL)
3.1 基于网络的UDTL(Network-based UDTL)
3.2 基于实例的UDTL(Instance-based UDTL)
3.3 基于映射的UDTL(Mapping-based UDTL)
3.4 基于对抗的UDTL(Adversarial-based UDTL)
4. 标签不一致的UDTL(Label-inconsistent UDTL)
4.1 部分UDTL(Partial UDT)
4.2 开放集UDTL(Open set UDTL)
4.3 通用UDTL(Universal UDTL)
5. 多域UDTL
5.1 多域适应(Multidomain Adaptation)
5.2 域泛化(Domain Generalization)
6. 数据集
6.1 公开数据集
(1)凯斯西储大学数据集(Case Western Reserve University,CWRU)
(2) 帕德博恩大学数据集(Paderborn University,PU)
(3) 江南大学数据集(JiangNan University,JNU)
(4) PHM2009年比赛数据集
(5)东南大学数据集(Southeast University,SEU)
6.2 数据分割
7. 对比研究
7.1 训练细节
7.2 标签一致UDTL
7.3 标签不一致UDTL
8. 进一步讨论
8.1 特征可迁移性
8.2 主干网络和瓶颈层的影响
8.3 负迁移
8.4 物理先验(Physical priors)
8.5 标签一致迁移
8.6 多域迁移
8.7 其它方面
9. 总结
摘要
近年来,智能故障诊断的发展很大程度上依赖于深度表征学习和大量的带标签数据。然而,机械设备通常在不同的工作环境下运行,或者目标任务与收集到的训练数据有不同的分布(域偏移问题)。此外,新收集的测试数据在目标域通常是无标签的,基于此提出基于无监督深度迁移学习(unsupervised deep transfer learning,UDTL)的智能故障诊断(Intelligent fault diagnosis,IFD)方法。虽然它已经取得了巨大的发展,但还没有建立一个标准的开放源代码框架和基于UDTL的IFD的对比研究。在本文中,我们构建了一个新的分类方法,并根据不同的任务对基于UDTL的IFD进行了全面的综述。通过对一些典型方法和数据集的比较分析,揭示了基于UDTL的IFD中一些尚未被研究的开放性和本质问题,包括特征的可转移性、主干网络的影响、负迁移、物理先验等。为了强调基于UDTL的IFD的重要性和可重复性,将向研究界发布整个测试框架,以促进未来的研究。综上所述,发布的框架和对比研究可以作为开展基于UDTL的IFD新研究的扩展接口和基础成果。代码框架可以在https://github.com/ZhaoZhibin/UDTL上找到。
关键词: 对比研究, 智能故障诊断(IFD), 可重复性(Reproducibility), 分类和调查(Taxonomy and survey), 无监督深度迁移学习(UDTL)
Ⅳ 标签不一致的UDTL
考虑到源域和目标域的标签集在实际应用中很难保持一致,因此研究标签不一致的UDTL具有重要意义。本文研究了三种标签不一致的迁移学习方式,包括部分UDTL、开放集UDTL和通用UDTL。
A部分UDTL
1)基本概念:部分UDTL,在[135]中提出,是一种迁移学习范式(paradigm),其中目标域标签集Ct是源域标签集Cs的一个子空间,即Ct⊂Cs。
2)部分对抗域适配(Partial Adversarial Domain Adaptation, PADA):目前流行的部分UDTL方法之一,由Cao等人提出[136]。PADA的模型类似于DANN,并进一步考虑将目标数据分配给源域私有类别(源域多出来的类别)的概率很小,并且对所有目标数据的标签预测都是平均的,量化每个源域类别的贡献
在用γ的最大值对其进行归一化之后,被用作类别级权重
通过将类别级权重应用于类别预测器和域鉴别器的损失上,可以减少属于源域私有类别的源域样本的贡献。预测损失和对抗损失公式如下:
其中
为了减少源域私有类别的影响,我们设计了一个基于UDTL的模型,将类别级权重应用到损失函数中,如图4-1所示。最终损失函数定义如下:

图4‑1基于PADA的UDTL模型
3)IFD的应用:在[137]中,构建了两个分类网络,利用两个网络的目标域标签预测值计算源域的类别级权值,然后对源域分类损失施加权重,以降低源域私有样本的影响。Li等人[138]在对抗迁移网络中加入了权值模块,构建了一种权值学习策略来量化源域样本的可迁移性。通过过滤不相关的源域样本,可以减少共享标签空间中不同域间的分布差异。Li和Zhang[139]提出了一种条件数据对齐技术来对齐健康数据的分布,以及一种预测一致性技术来对齐两个域中其他类别的分布。在[140]中,为了方便共享类别的正迁移,减少私有类别的负迁移,将每个源域类别的平均域预测损失作为类别级权值。为了避免潜在的负面影响并保持类间关系,Wang等人[141]提出通过添加一致性损失来单方面将目标域对齐到源域,这将使得对齐过的源域特征与预训练好的源域特征更接近。Deng等人[142]为每个类构造子域鉴别器以获得更好的灵活性,并提出了一种双层注意力机制,对子域鉴别器分配不同的注意力程度,对相关样本选择不同的注意力程度。Yang等人[143]提出通过训练一个域鉴别器来学习域不对称因素,源域样本在分布适配中加权,以滤掉无关知识。
B 开放集UDTL
1)基本概念:考虑到UDTL目标域的标签空间不确定,Saito等人[144]提出开放集域适配(Open Set Domain Adaptation,OSDA),目标域可以包含源域不存在的类的样本,即Cs⊂Ct。OSDA的目标是正确分类已知类别目标样本,并将未知类目标样本识别为其它类。
2)开放集反向传播(Open Set Backpropagation, OSBP):Saito等人[144]提出了一种基于对抗的UDTL方法,名为OSBP,旨在为未知类别制定伪决策边界。OSBP模型由特征提取器Gf和C+1分类器GC组成,其中C表示源类的数量。然后将GC的输出输入到softmax中,得到类别概率。将x归为类别c的概率定义为
为了正确地对源域样本进行分类,利用公式(6)中的预测损失来训练特征提取器和分类器。此外,通过训练分类器输出
我们设计了一个基于UDTL的模型,通过引入C+1分类器,并在损失函数中加入对抗思想,对未知类做出伪决策边界,如图4-2所示。鞍点用下面的min-max优化问题来解决:

图4-2基于OSBP的UDTL
3)IFD的应用:Li等人[145]提出了一种新的故障分类器来检测未知类,并进一步建立了卷积自编码器模型来识别[146]中新故障类型的数量。Zhang等人[147]提出了一种实例级加权UDTL方法,在特征对齐时应用目标样本的相似性。为了用未知类别识别目标样本,使用带有伪未知标签的目标域实例训练未知分类器。
C 通用UDTL
1)基本概念:You等人[148]提出了通用域适配(Universal Domain Adaptation,UDA),对标签集不施加先验知识。在UDA中,对于给定的源域标签集和目标域标签集,它们可能分别包含一个公共标签集和一个私有标签集。如果它与公共标签集中的一个标签相关联,UDA要求模型对目标样本进行正确分类,否则将其作为未知标签。让Cs表示源域标签集,Ct表示目标域标签集,
2)通用适配网络(Universal Adaptive Network, UAN):You等人[148]提出了通用适配网络,并利用域相似性和预测不确定性设计了一个实例级的可迁移性准则。如图12所示,UAN的模型与DANN相似,不同的是UAN增加了一个非对抗域鉴别器
源域样本和目标域样本的实例级可迁移性准则可以定义如下:
其中
非对抗域鉴别器Gd的损失为:
式中
通过训练UAN,可以最大限度地对齐源域数据和目标数据在共享标签集中的分布,减少类别差距。在测试阶段,对于目标样本

图4-3基于UAN的UDTL
3)IFD的应用:Zhang等人[149]提出了一种选择性UDTL方法。将分类权重应用于源域,实例权重应用于目标域。训练一个异常值标识符来识别未知的故障模式。Yu等人[150]提出了一种双边加权对抗网络,以对齐共享类别源域和目标域样本的特征分布,并分离开共享类别和异常类别样本。经过模型训练,以源域样本的特征表示为基础,建立极值理论(Extreme value theory,EVT)模型,并进一步用于目标域未知类样本的检测。
Ⅴ 多域UDTL
考虑到单个源域对于实际应用程序中的UDTL可能是不够的,考虑多域UDTL也是很重要的,它可以帮助了解域不变特性。本文研究了两种多域UDTL设置,包括多域适配(在训练阶段使用目标数据)和DG(在训练阶段不使用目标数据)。因为在多域UDTL中有多个源域,所以我们首先需要重新定义一些基本符号。设
A 多域自适配
1)基本概念:传统的基于单一源域的UDTL无法充分利用来自多源域的数据,可能无法找到私有关系和域不变特征。因此,多域适配的目的是利用有标签的多源域和未带标签的目标域来挖掘它们之间的关系和域不变特征。
2)多源无监督对抗域适应(Multi Source Unsupervised Adversarial Domain Adaptation, MS-UADA):多域适应主要有两种实现方式。一是特征应该是域不变的[151],即不同域之间的差距,包括源域和目标域在特征空间中,应该尽可能小。另一种方法是寻找与目标域最为相似的源域[152],[153]。第二种方法需要距离来衡量域之间的相似性。本文采用[151]中提出的MS-UADA方法实现多域自适应,其结构如图5-1所示。域鉴别器Gd的MS-UADA损耗定义如下:
为了缩小差距,Gf的特征应该混淆Gd,即使得Gd不能实现域分类。因此,训练过程可以看作是一个极大极小博弈,总损失为
其中λMS-UADA为权衡参数。优化的方法与DANN一致。

图5-1 基于MS-UADA的UDTL模型
3)IFD的应用:Zhu等人[154]提出了一种多域自适应对抗学习策略来捕获故障特征表示。Rezaeianjouybari和Shang[155]提出了一种新的多源自适应框架,该框架可以实现特征层和任务层的对齐。Zhang等人[156]提出了一种基于分类器对齐方法的对抗多域适配方法,从多个源域捕获域不变特征。He等[157]提出了一种基于多源域的k均值和空间变换。Wei等人[158]提出了一种基于分布相似性学习领域不变特征的多源适应框架。Zhang等[74]提出了一种基于MVD和MMD的增强迁移关节匹配方法,用于多域自适配。Li等人[159]提出了一种多域适配方法,通过域对抗训练来学习诊断知识。Huang等[160]提出了一种多源密集自适配对抗网络,可实现不同工况下的故障诊断。
B 域泛化(Domain generation,DG)
1)基本概念:DG是从多个源域学习共享知识,并将知识推广到目标域,这在训练阶段是看不到的。DG最大的区别在于,目标域的未带标签样本只在测试阶段出现。根据[161]的讨论,DG的核心思想是学习到的域不变特征应满足以下两个性质:1)Gf提取的特征应具有鉴别性,2)从不同源域提取的特征应具有域不变性。更详细的信息可参考文献[161]。
2)不变对抗网络(Invariant Adversarial Network,IAN):根据上文的描述,DG的性能取决于判别特征和域不变特征。域不变特征需要诊断模型来缩小不同域之间的特征差距。如第3节所述,对抗训练可以减少不同域之间特征的差距。如图5-2所示,DG采用了一种简单的基于DANN的对抗训练方法IAN[162],[163],通过对边缘分布进行对齐,帮助Gf提取域不变特征。IAN的结构如图13所示,域鉴别器Gd的IAN损耗定义如下:
Gf会混淆Gd。因此,IAN的总损失是一个极大极小博弈
其中

图5-2 基于IAN的UDTL模型
3)IFD的应用:Zheng等人[164]提出了一种基于先验诊断知识和IFD预处理技术的DG网络。Liao等人[165]提出了一种深度半监督DG网络,使用未标签和带标签的源域数据并借鉴了搬土距离(Earth-mover Distance)。Li等人[162]通过结合数据增强、对抗训练和基于距离的度量,提出了IFD中的DG方法。Yang等人[166]使用中心损失来学习不同源域的域不变特征来实现DG。Zhang等人[167]提出了一种基于单一鉴别器的条件对抗DG方法,以实现更好的迁移和较低的计算复杂度。Han等人[168]提出了一种基于DG的混合诊断网络,可通过三组损失和对抗训练部署到不可见的工况。
注明
1、由于本文翻译篇幅过大,本篇到此结束,下一篇将介绍数据集、对比研究
2、若需引用本文的公式、专业术语等内容建议再细读原论文核实;若本文对您的论文idea有帮助,建议引用原论文~
参考文献
[1]Z. Zhao et al., "Applications of Unsupervised Deep Transfer Learning to Intelligent Fault Diagnosis: A Survey and Comparative Study," in IEEE Transactions on Instrumentation and Measurement, vol. 70, pp. 1-28, 2021, Art no. 3525828, doi: 10.1109/TIM.2021.3116309.