大家好,我是小郭老师,硕士毕业于中科院,专注于运用 Python 深度集成 ANSYS 进行工程数值计算与仿真自动化开发,精通基于 Python实现ANSYS Workbench众多模块的全流程脚本驱动(建模、求解、后处理),并具备将复杂仿真流程封装为高效、可复用软件工具的专业能力,今天给大家分享一些ANSYS二次开发方面的干货。
也诚邀关注我的视频教程《ANSYS Workbench & Mechanical企业级二次开发程序与Python应用入门进阶》,详情见下文。

做科研写论文时,你是不是也遇到过这样的困扰:明明做了 ANSYS 模拟,却没法快速生成如下图所示的模拟瞬态数据和实验数据的对比,导致数值模型的可信度没法直观验证?亦或者,依据项目需求,一定得导出某些关键位置的瞬态响应结果?别急,今天小郭老师就带着大家用 Mechanical 的 Python 脚本开发,解决这个问题。

ANSYS Mechanical 脚本开发是基于Python(或 IronPython)语言,通过调用Mechanical模块的 API(应用程序接口)实现有限元分析流程自动化的技术手段。
它聚焦于Mechanical模块内部的建模、网格划分、边界条件设置、求解控制及后处理等全流程的程序化控制Mechanical,可通过两种方式入门:
• 一是利用 Mechanical自带的 “Record Script” 功能录制操作过程,生成基础脚本后再按需修改;
• 二是直接调用官方API 文档中的类与方法(如Model类用于模型管理、Mesh类用于网格控制),实现更灵活的定制。

瞬态数据导出关键命令:Named Selection + Result Sets在 Mechanical 的 Python 脚本开发中,要实现模拟数据的精准提取与后续对比,关键在于结合Named Selection(命名选择) 和Result Sets(结果集)。
先跟大家好好聊聊 Named Selection。它就像是给 ANSYS 里的 “特定对象组” 贴标签,是对已选出的实体、有限元对象、组合等进行的命名操作。在二次开发中,Named Selection可以用来定位目标边、面、几何体,乃至某个区域下的网格节点。
Named Selection(命名选择)主要有两种创建方式,直接法和间接法。在二次开发场景下,两者的实用性差异很大:
• 直接法:第一步得先选出要命名的点、线、面等对象,接着右键点击 “create named selections”,输入名称后点击 OK 完成创建。
这个方法听起来简单,但在二次开发里实现起来非常复杂,得结合ID概念和 SelectionManager类,代码逻辑比较绕,但能实现很复杂的功能。
关于这部分内容,我在《》第2章有做详细介绍,涵盖基本用法、示例等各种内容。
• 间接法:通过 Worksheet 进行选择。只要按照 Worksheet 给定的逻辑写代码,就能快速实现 Named Selection 创建,今天咱们的实战案例就用这种方法。

Result Sets(结果集)的创建方式如图所示。右键激活已经完成后处理求解的云图对象,选择Create Results at All Sets,即可生成TreeGroup对象。该对象内包含所有时步下的云图结果。
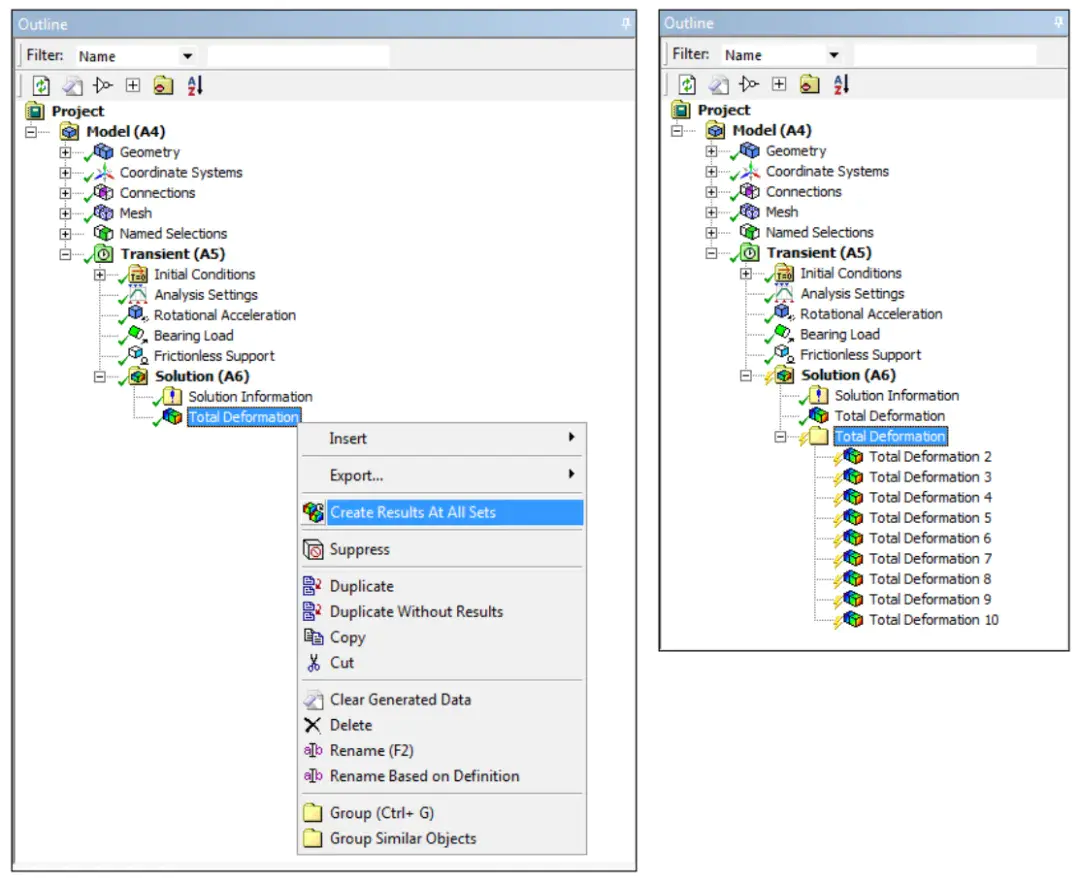
创建结果集的适用范围非常广,仅对极少数不适用,包括:
• Explicit Dynamics, Response Spectrum, Random Vibration, or Topology Optimization(显示动力学、响应谱、随机振动和拓扑优化分析)
• Probe Results(探针结果)
• Fracture Tool(断裂工具)
• Fatigue Tool(疲劳工具)
• Composite Failure Tool(复合材料失效工具)
步骤1:用 Named Selection 筛选目标检测点附近网格节点
首先要定位到目标检测点周围的网格节点,这就需要用间接法创建 Named Selection。我写了一个create_ns_by_points函数,如下所示:

咱们来看看关键逻辑:
1. 先初始化命名选择对象,设置名称和创建方式为 Worksheet;
2. 配置坐标轴(X、Y、Z 轴)的筛选规则,比如通过位置信息筛选节点,这里用 “Add” 和 “Filter” 组合确保筛选精准;
3. 计算每个坐标轴的边界值:根据检测点坐标和设定的公差(这里默认为0.05=5%),算出筛选范围。此外,还加了冗余判断 —— 当边界值接近 0 时(小于 1e-4),手动调整避免计算误差;
4. 最后生成命名选择,这样目标检测点附近的网格节点就被精准 “圈” 出来了。
例如,一电子器件冷却三维模型的目标检测点筛选结果如下图所示。可以看到,在给定的监测点坐标范围内(正负5%波动),仅筛选出一个网格节点。

步骤 2:插入后处理对象 + 求解
筛选出目标节点后,下一步就是获取对应的数据。先在分析方案的 Solution 里插入后处理对象,比如温度(Temperature),然后把这个后处理对象的 Location 设置为咱们刚创建的 Named Selection(也就是目标节点组),接着运行第一次求解,让 ANSYS 计算出该节点组在最终时刻下的结果。
步骤 3:创建求解集 + 二次求解
第一次求解后,要创建该后处理对象的 “求解集”,也就是CreateResultsAtAllSets。创建完求解集后,再运行一次求解。这样子,就能获取到整个分析过程中(比如瞬态分析的每个时间步)该节点组的所有结果数据。
步骤 4:遍历求解集 + 数据写入文件
最后一步,就是把结果数据导出来,方便后续和实验数据做对比。我写的export_trasient_file函数就能实现这个功能,核心逻辑包括如下四部分内容:
1. 以当前时间为后缀生成 CSV 文件,一个存所有节点的详细数据,一个存每个时间步的平均值(方便快速看整体趋势);
2. 写入表头,比如 “Time (s) Node_ID X (m) Y (m) Z (m) Value”,让数据结构清晰,后续用 Excel 或 Origin 处理时直接就能用;
3. 遍历每个时间步的结果集,提取时间、节点 ID、节点坐标、结果数值(比如温度值),逐行写入详细数据文件;
4. 同时,计算每个时间步下所有节点结果的平均值,写入平均值文件,后续画对比图时,既可以用详细数据,也能用平均值.
函数程序如下所示:

上面讲的流程,都浓缩在下面这段代码里了,每个关键步骤我都加了注释,大家拿到手稍作修改(比如改检测点坐标、结果类型)就能用:

05
可能有人会问,手动也能提取数据,为啥要费劲搞二次开发?
作为实战工程师,我举个实际工作中的例子:之前做过一个课题研究,需要处理瞬态温度分析结果,一共 360个时间步,每个时间步要提取10个检测点的数据,重复性工作量大,还很容易出错。
用上面的脚本,设置好坐标后点击运行,2 分钟就能出所有 CSV 文件。之后,再用 Origin 导入数据,10 分钟就能画出模拟与实验的对比曲线图,效率直接翻十几倍!
而且,这个脚本还能灵活修改。比如,把AddTemperature()改成AddEquivalentStress()就能提取应力数据,调整monitor_coords就能换检测点,甚至加个循环能同时处理多个检测点,完全适配不同的项目需求。
实际上,结合ANSYS Mechanical API和Python脚本开发,可以实现Mechanical的完全脚本化和高度可定制化,例如模板开发、自定义载荷、后处理及结果等。




