功放测试关注哪些指标
功放是发射电路的核心器件,特别是对于宽带传输,功放对非恒包络的调制方式影响更大,可以说PA是非恒包络调制方式发射机的指标和工作时间的决定性器件。


功放的调试和测试一般用矢网调匹配,调增益,调功率和效率,用信号源和频谱仪调线性。
两套设备反复使用,最终实现功放的功率、线性、效率的最佳匹配。

为什么要用两套仪表测试功放,一个功放从选型到输出需要测试哪些数据?
1.匹配
功放是一个有源器件,为了获得高功率输出,根据P=U2/R,功率越大的管子,阻抗越小,为了信号的最大功率传输,必须要做阻抗匹配。而矢网就是完成实际操作测试的sourcepull和loadpull的仪表。完成了输入输出的匹配就是完成了初步的功放匹配设计。



2.频率和功率的扫描
输入输出匹配完,就要对功放的工作频率和输出功率进行测试,矢量网络分析仪可以实现对频率和功率的扫描,完成功放的带宽和功率的范围测试。

3.功放的线性
在前面的文章中讲过,对于宽带功放来说,功放有记忆效应,而记忆效应是制约DPD的效果的关键因素。功放记忆效应的产生是因为AM-PM的发散,要想DPD实现很好的线性化效果,准确的AMPM失真模型必不可少。而矢量网络分析仪可以测试功放的AM-PM失真,为DPD模型提供准确的测试数据。

AMPM失真是衡量功放线性化更为准确的数据。但是对于射频工程师来说,无法直观的去显示功放的失真。
功放的失真一般用两种方式来体现,一是互调。
互调对于做功放模块的工程师来说是常用的指标。




注意看上面双音信号的泰勒级数展开,双音信号不管是不是经过非线性器件,都会有互调信号的产生,这也就是为什么功放回退到一定程度,互调不变化的原因。
一般用信号源和频谱仪测试互调指标。
互调于输出功率和OIP3的关系如下面公式。
IM3 (dBm) = 3Pin (dBm) – 2IIP3 (dBm) + G (dB)
= 3Pout (dBm) – 2IIP3 (dBm) –2G (dB)
= 3Pout (dBm) – 2OIP3 (dBm)
虽然互调的指标能够准确的衡量功放的失真度。但是对整机功放的工程师,EVM或者ACPR更能直观的显示出最终功放所需求的指标。


从通信系统的角度来出发,系统工程师更关注信号的失真,而不是功放的失真,系统工程师确定输入信号的指标和输出的指标,那么留给功放的指标也就可以确定。所以在通信上更多的用EVM和ACPR来衡量功放的失真。
EVM给功放留的量可以根据EVM的累加公式计算
EVM= +
+

在测试之前,还需要摸一下宽带信号的峰均比,因为有的波形的销峰是基带端在销峰,有的是留给功放去硬销峰。
基带销峰和功放硬销峰的区别在于功放能不能产生新的失真,这对功放的设计很重要。

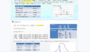
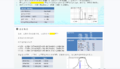
调用频谱仪的CCDF模版就可以测试宽带信号的峰均比了,注意有99%,99.9%,99.99%的区别。
4.谐波
除了上面的线性指标需要关注,也要关注功放的谐波,谐波关系到功放后面滤波器的设计和选型。

5.效率

功放线性指标很重要,效率同样重要,关注线性的同时注意关注效率是否达到了设计要求,要做到线性和效率的折中。