利用NVIDIA Grace Blackwell加速AI驱动的工程设计和科学应用

内容提要
内容提要
● Cadence 借助 NVIDIA 最新 Blackwell 系统,将求解器的速度提升高达 80 倍
● 基于全新 NVIDIA Llama Nemotron 推理模型,携手开发面向工程设计和科学应用的全栈代理式 AI 解决方案
● 率先采用面向 AI 工厂数字孪生的 NVIDIA Omniverse Blueprint,旨在实现高效的数据中心设计和运营
中国上海,2025 年 3 月 24 日 —— 楷登电子(美国 Cadence 公司,NASDAQ:CDNS)今日宣布扩大与 NVIDIA 的多年合作,重点推动加速计算和代理式 AI 的发展。此次合作旨在解决全球关键技术挑战,推动各行业创新发展,实现实质性突破。
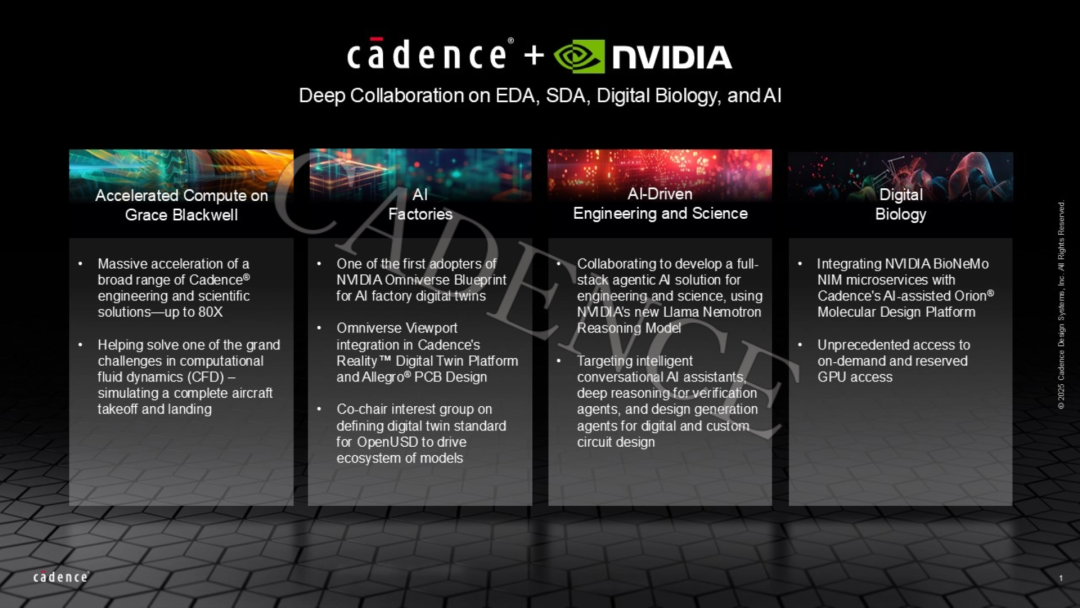
Cadence 通过集成 NVIDIA 加速计算技术,推动多个行业的科技创新。基于 NVIDIA 的最新 Blackwell 架构,Cadence® 系列工程和科学解决方案实现大规模加速,使设计人员能够攻克过去难以解决的更大、更复杂的难题。此次合作的成果如下:
● 计算流体力学仿真时间缩短高达 80 倍,从几天缩短至几十分钟
● Cadence Spectre X Simulator 提速高达 10 倍
● 3D-IC 设计和对于热力、应力及翘曲分析提速高达 7 倍
Cadence Fidelity CFD 平台利用 Blackwell 解决最复杂的流体力学问题
Cadence Fidelity CFD 平台利用 Blackwell 解决最复杂的流体力学问题
Cadence 利用 NVIDIA Blackwell 平台帮助解决计算流体力学 (CFD) 的一大挑战:在飞行包线最具挑战性的部分(起飞和降落期间)对整架飞机进行仿真。借助 Cadence Fidelity CFD 平台,Cadence 成功在 NVIDIA GB200 GPU 上运行了数十亿网格单元的仿真,用时不到 24 小时。而在此之前,该仿真过程需要依赖一个拥有数十万内核的 Top 500 CPU 集群,并耗时数天才能完成。Cadence 将继续利用 Blackwell 测试仿真的极限,帮助航空航天业减少风洞测试次数、降低成本并加快上市进程。
此外,Cadence 还与 NVIDIA 携手开发面向电子系统设计以及科学应用的全栈代理式 AI 解决方案。此次合作将引入突破性代理技术,将 Cadence JedAI 平台与 NVIDIA 的 NeMo 生成式 AI 框架和新发布的 NVIDIA Llama Nemotron 推理模型相整合,提高设计生产力,例如:
● 智能对话式 AI 助手,可提高用户生产力和创新能力
● 基于底层设计资源和验证代理的深度验证推理
● 利用设计代理,实现数字和定制电路的设计生成与优化
此外,Cadence Molecular Sciences(OpenEye)正在将 NVIDIA BioNeMo NIM 微服务与 Cadence 的云原生分子设计平台 Orion® 整合。此次合作旨在通过结合卓越的云端 AI 和 GPU 技术,加速药物研发工具的革新。Orion 具有突破性的按需和预留 GPU 访问能力,能够帮助全球科学家开展大规模复杂计算,革新治疗性药物设计。NIM 微服务扩展了 Orion 的能力,具体如下:
● 用于对蛋白三维结构进行重头预测的 AI 模型
● 小分子生成式 AI
● 用于预测抗体特性的基础 AI 模型
Cadence 正利用 NVIDIA 的先进数字孪生技术加速 AI 基础设施的构建。能够成为首批采用面向 AI 工厂数字孪生的 NVIDIA Omniverse Blueprint 的企业之一,Cadence 深感自豪。此次合作推动了一致且准确的模型创建,从而实现数据中心数字孪生的快速发展。NVIDIA Omniverse Viewport、Cadence Allegro® X Design Platform 与 Cadence Reality™ Digital Twin Platform 的整合,使设计人员能够以全新的视角,更精确地洞察整个电子系统设计流程。下游用户可利用数据进行分析,并用于器件和 BOM 管理、制造接口、系统级质量以及机械和工业设计等领域。NVIDIA 和 Cadence 在打造高质量模型生态系统方面占据前沿地位,为设备制造商和数据中心公司开启快速、信心十足地创建数字孪生解决方案的大门。
“Cadence 正在 NVIDIA 最新的 Grace Blackwell NVL72 平台上加速 AI 驱动的 EDA 以及系统设计和分析工作负载。我们能够帮助交付符合当前需求的基础设施 AI 和代理式 AI,并重塑物理 AI 和科学 AI 的仿真基础。”Cadence 总裁兼首席执行官 Anirudh Devgan 博士表示。“凭借这些技术突破,我们能够在数小时内完成先前难以实现的大规模复杂系统仿真,其中包括一些迄今为止规模最大、最精确的整机仿真。”
“加速计算和代理式 AI 正在重新定义各行各业的创新标准。”NVIDIA 创始人兼首席执行官黄仁勋说道。“NVIDIA 和 Cadence 携手合作,不断突破技术边界,在仿真、优化和设计方面取得重大进展,助力提升效率、缩短产品上市时间,并推动科学探索迈向新高度。”



